ASL Alphabet Recognition
A deep learning system classifying ASL hand gestures using CNNs. Compared a lightweight baseline against VGG16/ResNet transfer learning on ~27,000 labelled images. The baseline achieved 100% validation accuracy in under 60 seconds.
A deep learning system for classifying American Sign Language hand gestures. The project compared multiple CNN architectures — a lightweight custom baseline against industry-standard transfer learning approaches (VGG16, ResNet50) trained on a dataset of approximately 27,000 labelled images.
The goal was to understand the real trade-offs between model complexity and performance: does a deeper, pre-trained network always win? The results were surprising.
Three architectures were evaluated side by side:
- Baseline CNN — a lightweight custom model designed for speed
- VGG16 — fine-tuned from ImageNet weights
- ResNet50 — fine-tuned from ImageNet weights
Each model was trained on the same dataset split and evaluated on held-out validation data. Training was done on Google Colab with GPU acceleration.
The baseline CNN was intentionally lean — three convolutional blocks with max pooling, followed by a dense head with dropout. Simple enough to train in under a minute, expressive enough to learn the task.
def build_model(num_classes=29):
model = Sequential([
Conv2D(32, (3,3), activation='relu',
input_shape=(64, 64, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3,3), activation='relu'),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(num_classes, activation='softmax'),
])
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'],
)
return modelThe baseline model outperformed the transfer learning approaches on this task — 100% validation accuracy in under 60 seconds of training. The dataset was clean and domain-specific enough that a simple architecture, well-tuned, was sufficient.
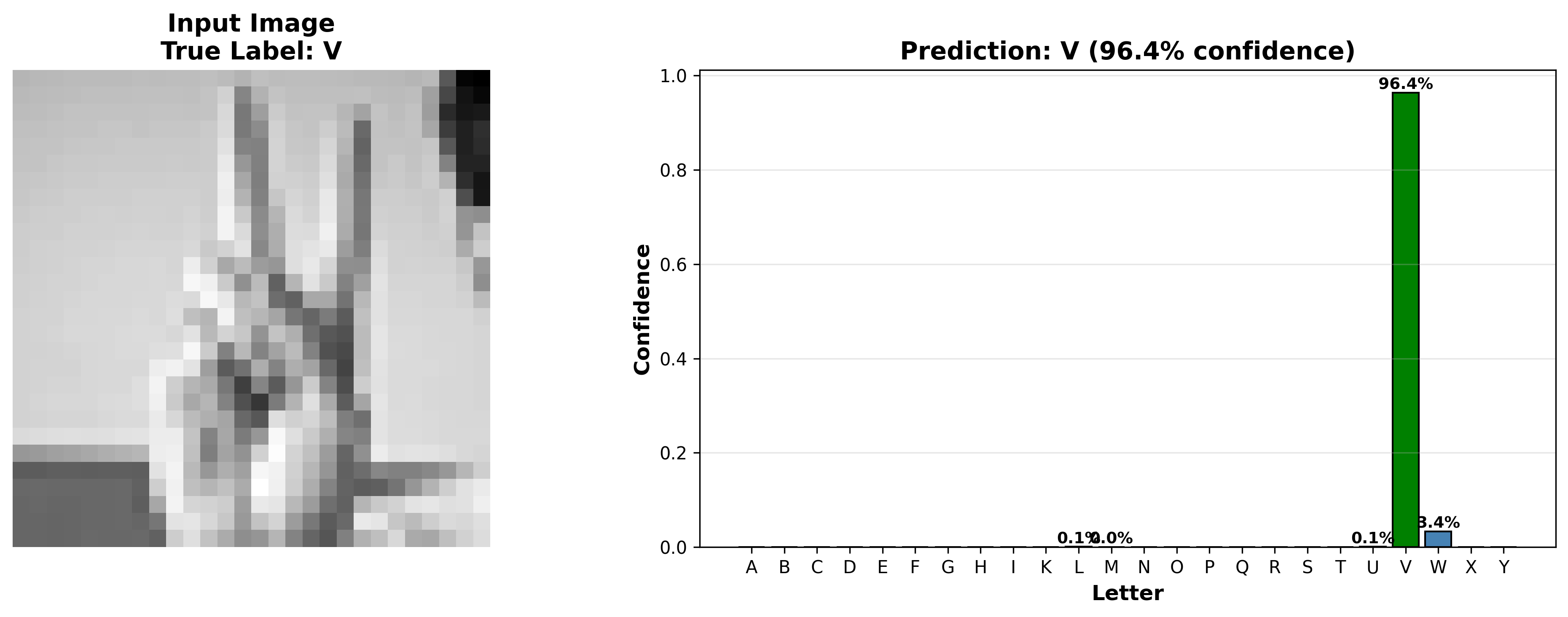
Training curves and the per-class confusion matrix from the final baseline evaluation run.
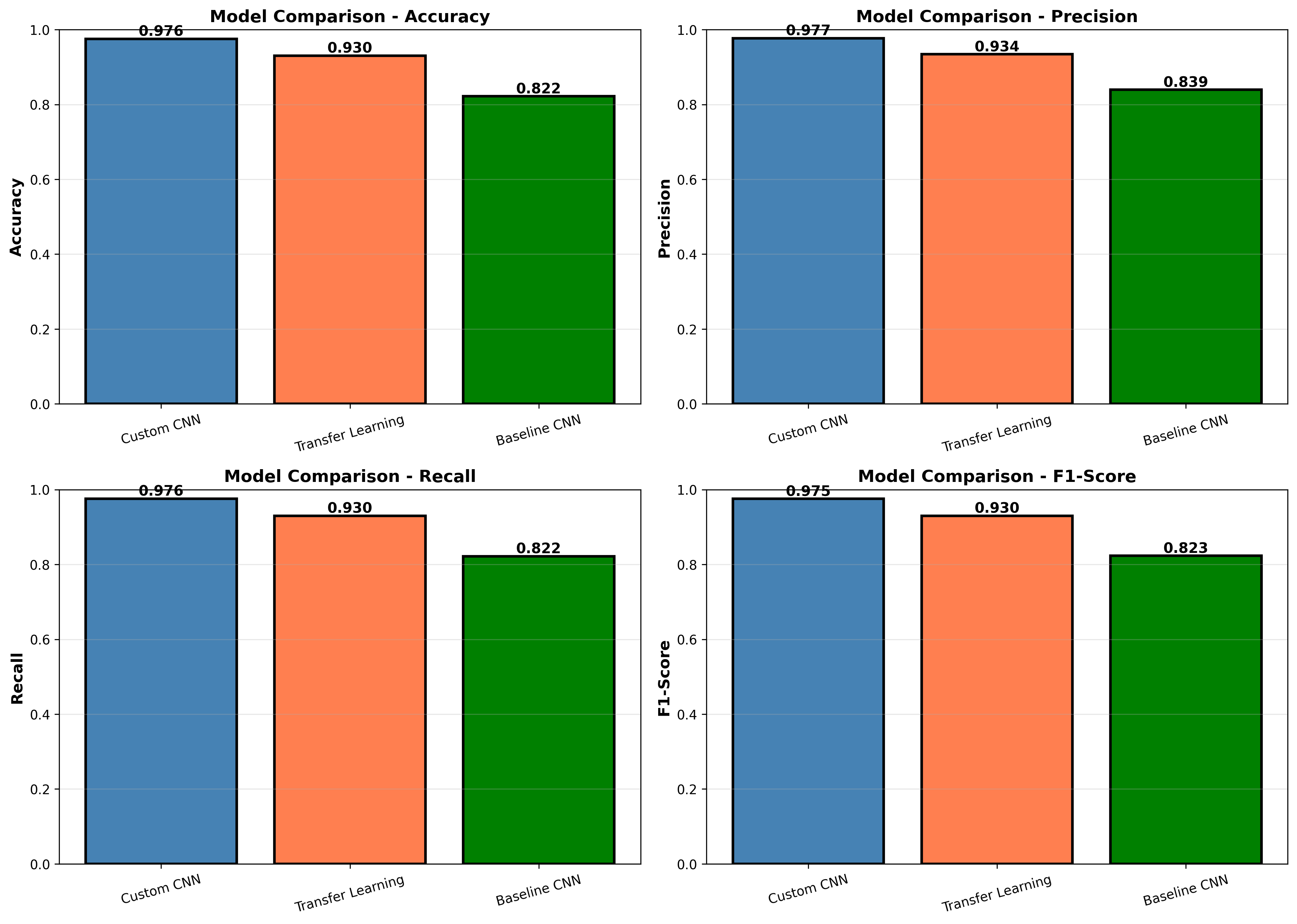
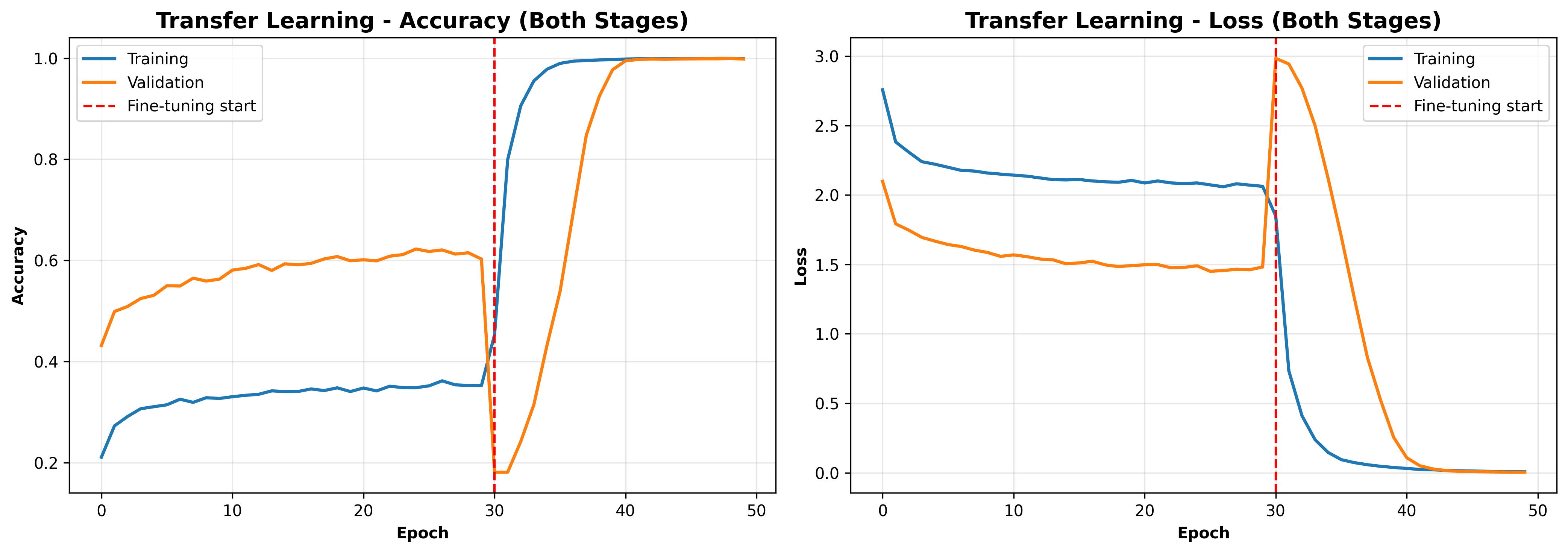
Transfer learning is a powerful default, but not always the right answer. For well-constrained, domain-specific tasks with clean data, a simple purpose-built model can match or exceed large pre-trained networks at a fraction of the compute cost.
The other lesson: benchmarking matters. Without running all three architectures on the same data under the same conditions, I'd have guessed the more complex models would win.
