ArchComm
Does Agent Architecture Shape Emergent Language? A Comparative Study of Communication in Multi-Agent Referential Games
A controlled empirical study investigating whether neural agent architecture shapes emergent language structure in multi-agent referential games. Compares LSTM, GRU, Transformer, and MLP across 10 random seeds each.

When two artificial agents must cooperate to win a game — with no shared language and no human supervision — they develop a communication protocol from scratch. Prior work has shown these emergent protocols sometimes exhibit properties reminiscent of natural language, but almost always uses recurrent architectures (LSTMs) without questioning whether that choice matters.
This paper asks a simple question: does the architecture of the agent shape the structure of the language it develops? We run a controlled comparison of four sender-receiver architecture pairs — LSTM, GRU, Transformer, and MLP — in a Lewis signaling game, holding everything else fixed.
Compositionality — the property that meaning is systematically built from parts — is one of the defining features of human language. A finite vocabulary can express an infinite range of meanings because sentences are structured, not arbitrary.
Multi-agent referential games offer a way to study whether compositionality emerges naturally from communicative pressure alone, or whether it requires specific conditions. Prior work treats architecture as an implementation detail. We treat it as the independent variable.
The game: a sender observes a 32-dimensional feature vector (the target) and produces a message of up to 5 symbols (vocabulary size 50). The receiver sees the message alongside 5 candidate objects and must identify the target. All reward comes from task success — there is no explicit pressure toward compositional structure.
We compare four architecture pairs, each run with 10 independent random seeds:
- LSTM — long short-term memory; primary baseline per prior literature
- GRU — gated recurrent unit; lighter recurrent variant for within-family comparison
- Transformer — self-attention encoder; no inherent sequential inductive bias
- MLP — feedforward network; no sequential processing; ablation baseline
All architectures use embedding dimension 64 and hidden dimension 256. Transformer agents are additionally evaluated under Gumbel-Softmax training (GS), since REINFORCE proved unstable for attention-based communication.
Evaluation metrics: task accuracy, topographic similarity (topo ρ — Spearman rank correlation between pairwise meaning distances and message distances), symbol entropy, and effective vocabulary size.
The main finding: recurrent architectures produce more compositionally organised languages than non-recurrent architectures, even when task accuracy is comparable.
| Architecture | Val Acc | Topo ρ | Entropy | Eff. Vocab |
|---|---|---|---|---|
| LSTM | 0.630 ± 0.037 | 0.192 ± 0.018 | 6.13 ± 0.34 | 19.9 |
| GRU | 0.662 ± 0.055 | 0.181 ± 0.028 | 6.36 ± 0.25 | 24.6 |
| Transformer (REINFORCE) | 0.271 ± 0.139 | 0.134 ± 0.008 | 0.99 ± 1.97 | 4.4 |
| Transformer (GS) | 0.575 ± 0.037 | 0.149 ± 0.039 | 5.04 ± 0.51 | 11.1 |
| MLP | 0.572 ± 0.042 | 0.136 ± 0.029 | 5.35 ± 0.73 | 10.0 |
Recurrent architectures (LSTM, GRU) achieved higher topographic similarity than non-recurrent baselines (MLP, Transformer) despite comparable task accuracy — suggesting that sequential inductive bias specifically facilitates compositional language structure, beyond what communicative pressure alone produces.
Transformer agents trained with REINFORCE failed to learn in 8 out of 10 seeds, collapsing to a single repeated symbol. Under Gumbel-Softmax training all seeds converged, but topographic similarity remained lower than recurrent models. The failure was in the training signal; the lower compositionality is architectural.
The near-identical results of LSTM and GRU suggest recurrence itself — not LSTM-specific gating mechanics — is the relevant inductive bias. Compositionality is not simply a byproduct of communicative success; it is also a function of what kind of learner is doing the communicating.
Built on the EGG (Emergence of Language in Games) toolkit. The game loop, REINFORCE training, and metric evaluation across all five conditions.
"""
Referential game dataset and loss.
Protocol:
- Sender sees a target object feature vector.
- Receiver sees (n_distractors + 1) candidate vectors in shuffled order
and must identify which is the target using the sender's message.
- Loss: cross-entropy over candidate positions (receiver output).
- Reward for REINFORCE: 1.0 if receiver correct, 0.0 otherwise.
"""
import torch
from torch.utils.data import Dataset
import egg.core as core
class ReferentialDataset(Dataset):
def __init__(self, n_objects, n_features, n_distractors, n_samples, seed=42):
rng = torch.Generator()
rng.manual_seed(seed)
prototypes = torch.rand(n_objects, n_features, generator=rng)
self.prototypes = prototypes
indices = torch.randint(0, n_objects, (n_samples,), generator=rng)
self.targets = prototypes[indices]
self.labels = torch.zeros(n_samples, dtype=torch.long)
distractor_idx = torch.zeros(n_samples, n_distractors, dtype=torch.long)
for i in range(n_samples):
pool = list(range(n_objects))
pool.remove(int(indices[i]))
chosen = torch.randperm(len(pool), generator=rng)[:n_distractors]
distractor_idx[i] = torch.tensor([pool[c] for c in chosen])
distractors = prototypes[distractor_idx]
all_candidates = torch.cat([self.targets.unsqueeze(1), distractors], dim=1)
perm = torch.stack([torch.randperm(n_distractors + 1, generator=rng) for _ in range(n_samples)])
self.candidates = torch.stack([all_candidates[i][perm[i]] for i in range(n_samples)])
self.labels = torch.tensor([(perm[i] == 0).nonzero(as_tuple=True)[0].item() for i in range(n_samples)])
def __len__(self):
return len(self.targets)
def __getitem__(self, idx):
return self.targets[idx], self.labels[idx], self.candidates[idx]
def referential_loss(sender_input, message, receiver_input, receiver_output, labels, aux_input=None):
"""Cross-entropy loss + accuracy for the referential game."""
loss = torch.nn.functional.cross_entropy(receiver_output, labels, reduction="none")
acc = (receiver_output.argmax(dim=-1) == labels).float()
return loss, {"acc": acc}
def build_game(sender, receiver, cfg):
return core.SenderReceiverRnnReinforce(
sender, receiver, referential_loss,
sender_entropy_coeff=cfg.get("sender_entropy_coeff", 0.01),
receiver_entropy_coeff=cfg.get("receiver_entropy_coeff", 0.001),
)
def build_game_gs(sender, receiver, cfg):
"""Gumbel-Softmax variant — fully differentiable, no entropy coefficients."""
return core.SenderReceiverRnnGS(
sender, receiver, referential_loss,
length_cost=cfg.get("length_cost", 0.0),
)Learning curves and message length distribution across all five conditions, mean ± 1 std across 10 seeds.
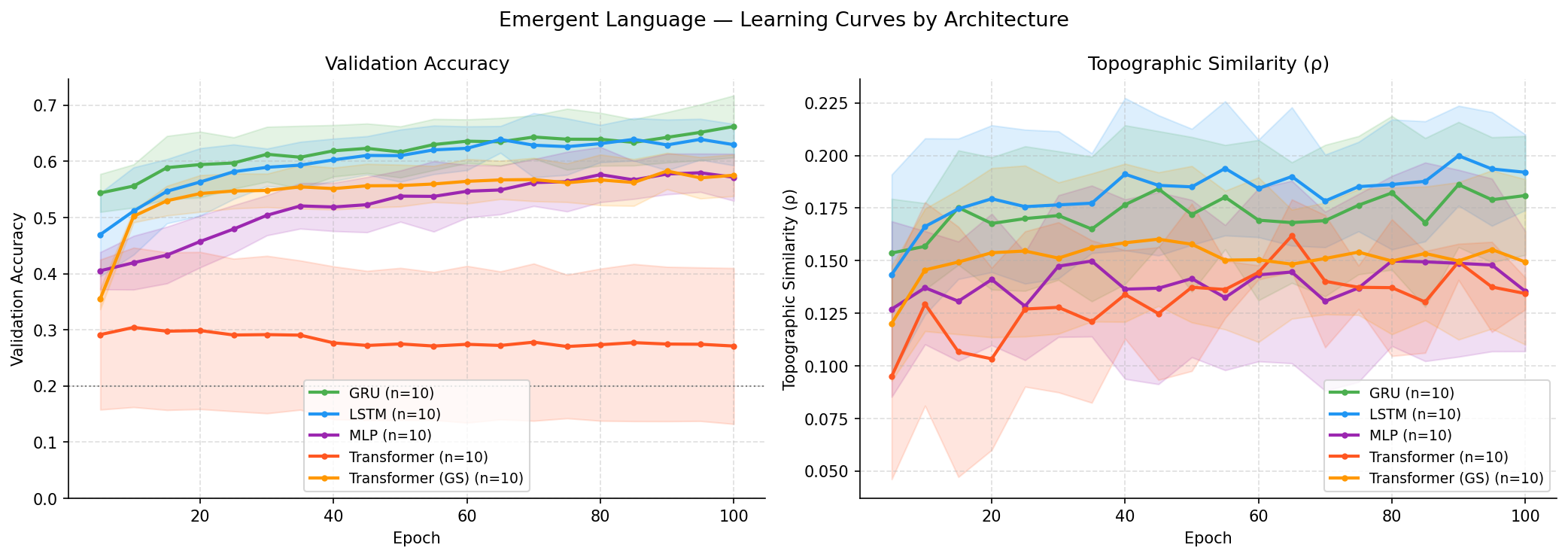
Architecture is not a neutral implementation detail. The inductive bias you build into an agent — specifically, whether it processes sequences step-by-step — shapes the kind of language it develops, independently of whether it succeeds at the task.
Running 10 seeds per condition and tracking variance was as important as the point estimates. The Transformer's REINFORCE failure was only visible in aggregate — individual seeds would have been misleading. Multi-seed evaluation is non-negotiable for emergent communication research.
I also learned that writing up research is a different skill from doing it. Making the methodology precise enough that someone else could replicate it, and separating what the results actually show from what you hoped they would show, took as much effort as the experiments themselves.

